
Data source:
- Heap table (no clustered index)
Purchasing.PurchaseOrderHeader_test2,006,000 rows, no nonclustered indexes - Heap table (no clustered index)
Purchasing.PurchaseOrderDetail_test1,769,000 rows, no nonclustered indexes
Original query
SELECT
PurchaseOrderID, RevisionNumber, Status, TotalDue, ModifiedDate, DueDate
FROM Purchasing.PurchaseOrderHeader_test A
CROSS APPLY (
SELECT TOP 1 DueDate
FROM Purchasing.PurchaseOrderDetail_test B
WHERE A.PurchaseOrderID = B.PurchaseOrderID
ORDER BY DueDate DESC
) C;
Estimated Execution Plan 1
Estimated Subtree Cost: 586.232 → far too high, indicating long execution time and heavy server load.
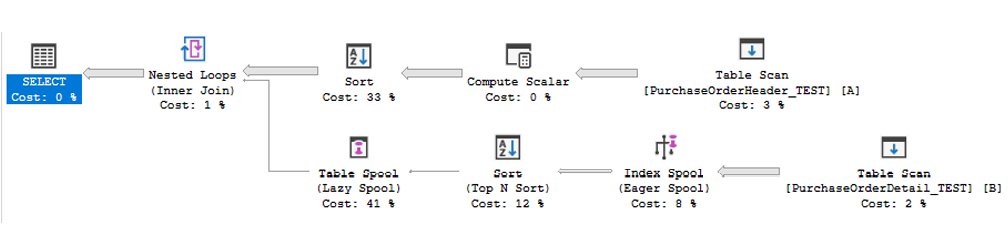
The plan shows:
- Table Scans on both tables — undesirable
- Sort (33%) — also undesirable
- Nested Loops requires sorted input, causing the expensive sort
- Lazy Spool and Eager Spool — additional overhead
Creating indexes
Index 1 – PurchaseOrderHeader
CREATE INDEX IX_TEST1 ON Purchasing.PurchaseOrderHeader_test
(PurchaseOrderID)--Where condition column
INCLUDE (RevisionNumber, Status, TotalDue, ModifiedDate);--After SELECT columns out of WHERE conditionIndex 2 – PurchaseOrderDetail
CREATE INDEX IX_TEST2 ON Purchasing.PurchaseOrderDetail_test
(PurchaseOrderID, DueDate DESC);--WHERE condition and ORDER BY columnsEstimated Execution Plan 2
Estimated Subtree Cost: 259.148 → better, but still not ideal.
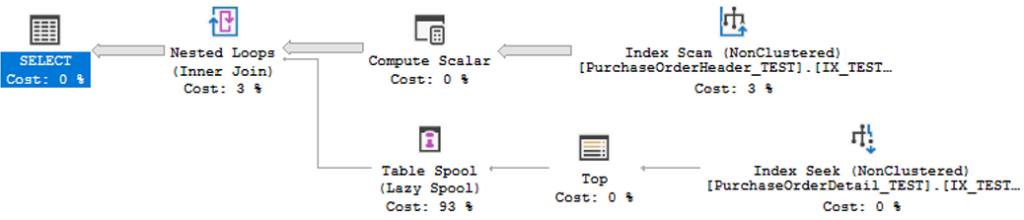
Remaining issues:
- Lazy Spool = 93% of total cost
- Both tables have similar row counts → Nested Loops is not the best join choice
Query rewrite
Replace TOP 1 ... ORDER BY (iteration) with an aggregate:
SELECT
PurchaseOrderID, RevisionNumber, Status, TotalDue, ModifiedDate, DueDate
FROM Purchasing.PurchaseOrderHeader_test A
CROSS APPLY (
SELECT MAX(DueDate) AS DueDate
FROM Purchasing.PurchaseOrderDetail_test B
WHERE A.PurchaseOrderID = B.PurchaseOrderID
) C;Estimated Execution Plan 3
Estimated Subtree Cost: 20.697 → a massive improvement.
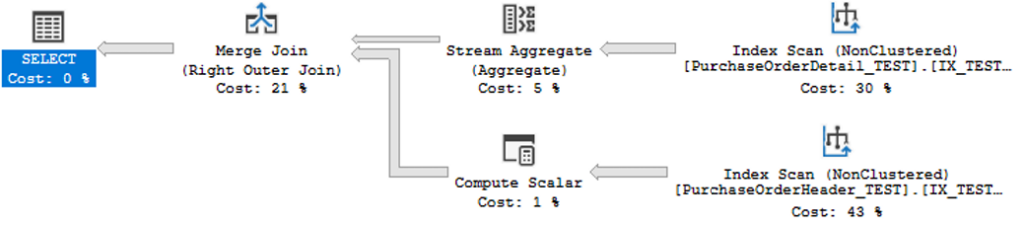
The optimizer switched to:
- Merge Join – efficient when both tables have similar row counts
- Stream Aggregate – cheaper than iterative TOP 1
- Index Scan – considered optimal in this scenario
Conclusion
It is crucial to create indexes that are not only present but actually useful and efficient. At the same time, the query itself must be written optimally — sometimes rewriting the query yields a bigger improvement than adding indexes.
Optimization is not a silver bullet. Two queries may have similar execution times, but the less optimal one will:
- put more load on the server
- slow down other queries
- increase lock durations
Which can negatively impact overall system performance.